

{kind=link}
If your site still shows the same static products to everyone, you’re leaving money on the table.
Top performers using ecommerce recommendation engines see roughly 40% more revenue and 20–40% higher AOV.
An ecommerce recommendation engine analyzes behavior and product and context signals to serve smart product suggestions across site, email, and ads in real time.
This post explains how these engines work, which approach fits your catalog, and the small experiments to run first so you can lift conversion and AOV fast.
Core Explanation of Ecommerce Recommendation Engines

An ecommerce recommendation engine is software that analyzes how people shop, what products share in common, and context clues to automatically suggest items across your site, emails, and ads. These engines track clicks, views, purchases, cart adds, time spent on pages, and search queries. They build profiles of individual shoppers and catalog understanding. Then they match users to products in real time, showing suggestions on homepages, product pages, cart screens, emails, and paid media.
The main job here is pattern recognition at scale. When someone views a laptop, the engine instantly scans millions of past interactions to figure out which products similar users bought next, which items have compatible specs, and which accessories get bundled together most. It ranks those options by relevance and delivers a curated list in milliseconds. This runs continuously, updating recommendations as the session evolves and new signals come in.
Recommendation engines directly move the metrics that matter. Personalization typically drives a 5 to 15% revenue lift. Top performers generate roughly 40% more revenue than stores using generic merchandising. Conversion rates improve when shoppers see products aligned with their intent. Average order value goes up when complementary items appear at the right moment. Retention improves because 56% of customers are more likely to return to sites offering relevant recommendations. The opposite is also measurable. 74% of customers report frustration when content feels generic, and 76% expect personalized interactions by default.
At the system level, a recommendation engine has five core pieces:
Data inputs pull in event streams capturing views, clicks, purchases, reviews, ratings, session duration, cart events, search terms, and product metadata like titles, descriptions, categories, prices, images, and inventory status.
Real-time processing layer ingests behavioral signals as they occur, updates user profiles and session state, and triggers re-ranking when new information arrives (like a product added to cart).
Algorithm layer applies collaborative filtering to find user or item similarities, content-based filtering to match product attributes to user preferences, and hybrid models that blend both approaches for higher accuracy.
Ranking layer scores candidate products by predicted relevance, applies business rules (exclude out-of-stock items, prioritize high-margin SKUs), and personalizes the final order based on context such as device type, time of day, or seasonal trends.
Delivery layer serves recommendations via APIs to web frontends, mobile apps, email platforms, and ad systems. It supports sub-second response times and failover to cached or fallback suggestions during traffic spikes.
Categories of Ecommerce Recommendation Systems
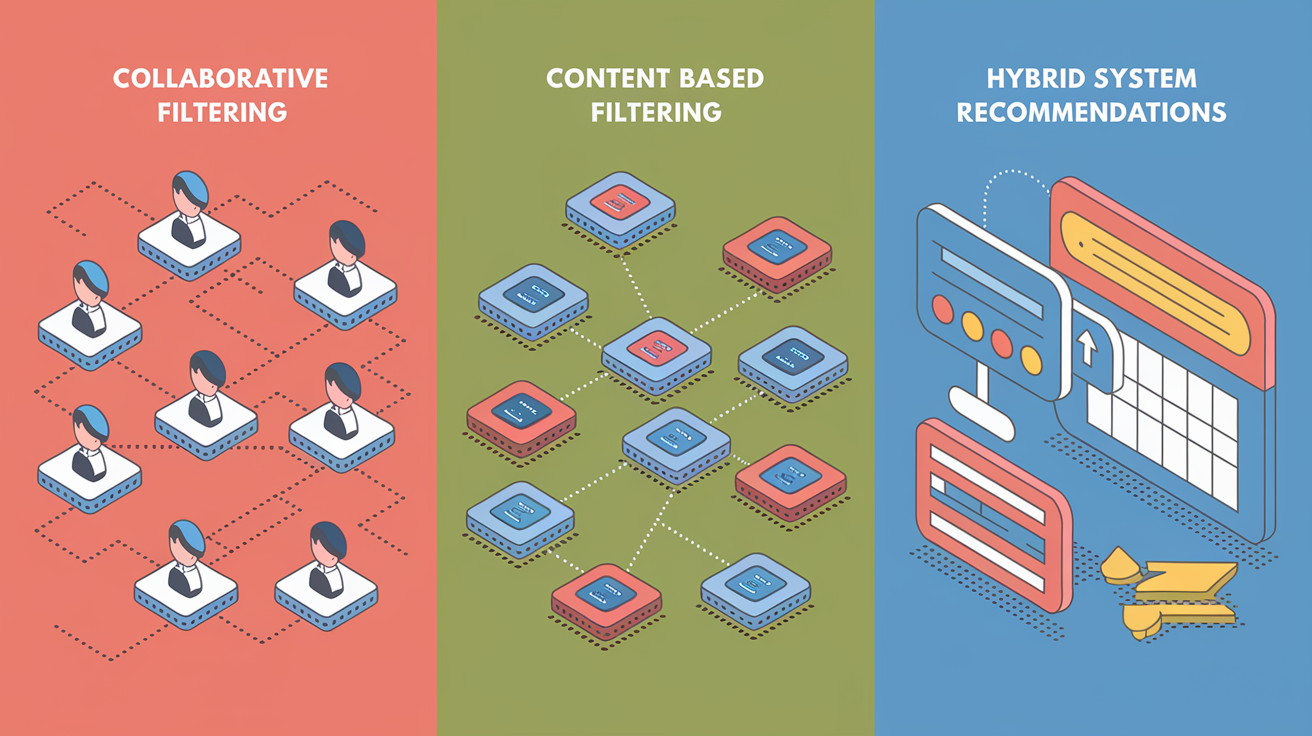
Recommendation systems fall into three primary categories. Each has distinct data requirements and use cases. Choosing the right category depends on available signals, catalog size, and cold-start constraints.
Collaborative Filtering
Collaborative filtering predicts a user’s preferences by identifying patterns across similar users or items. User-based collaborative filtering finds shoppers with overlapping purchase or browsing histories and recommends items those neighbors bought. Item-based collaborative filtering identifies products frequently viewed or purchased together and suggests them as a set. Both approaches rely on interaction volume. The more clicks, purchases, and ratings the system observes, the stronger the patterns become. Collaborative filtering works well when interaction data is rich but struggles with new users or new products that lack behavioral history.
Content-Based Filtering
Content-based filtering uses product metadata (titles, descriptions, categories, brands, prices, images, technical specs) to match items to a user’s known preferences. If a shopper consistently views smartphones with large screens and high-resolution cameras, the engine scores similar devices highly. This approach works well for new products because it depends on attributes rather than interaction history. The trade-off is that content-based systems can over-specialize, recommending only narrow variations and missing cross-category opportunities that collaborative methods would surface.
Hybrid Systems
Hybrid recommendation engines combine collaborative and content-based filtering to offset each weakness. A common pattern uses collaborative filtering to generate a broad candidate set, then applies content-based scoring to refine and diversify results. Another approach dynamically switches between methods: content-based for cold-start users, collaborative for those with rich histories. Hybrid systems consistently outperform single-method engines in both relevance and business metrics. That’s why most production-scale platforms adopt hybrid architectures by default.
Algorithms That Power Product Recommendations

Traditional algorithms form the foundation of many recommendation systems. K-nearest neighbors (KNN) identifies the closest users or items in a multidimensional feature space and surfaces products from those neighbors. Matrix factorization decomposes large user-item interaction matrices into latent factors, capturing hidden preferences that explain observed behavior. These methods are computationally efficient and interpretable, making them suitable for catalogs under one million SKUs and user bases with consistent engagement patterns.
Machine learning expands recommendation capabilities by learning complex, nonlinear relationships between features. Logistic regression and gradient-boosted decision trees predict click or purchase probability using dozens of input signals: recent views, category affinity, price sensitivity, session length, device type. These models train on historical outcomes and retrain regularly as new data arrives. Feature engineering becomes critical. Derived signals like “percentage of electronics purchases in the last 30 days” or “average dwell time on product pages” often outperform raw event counts.
Deep learning models handle even larger feature sets and richer interaction sequences. Recurrent neural networks (RNNs) and transformers process session sequences (view, view, add-to-cart, view) to predict the next action. Two-tower architectures encode users and items into high-dimensional vector embeddings, then retrieve candidates via approximate nearest neighbor (ANN) search. These embeddings capture semantic similarity: a user interested in “wireless headphones” will see recommendations for Bluetooth earbuds even if explicit interaction overlap is low. Deep learning works well at scale but requires substantial data volume, GPU infrastructure, and careful tuning to avoid overfitting.
Ranking algorithms sit atop candidate generation and decide final display order. Pointwise rankers score each item independently. Pairwise rankers compare items in pairs to learn relative preference. Listwise rankers optimize the entire recommendation slate for diversity, relevance, and business objectives like margin or stock clearance. Many production systems use learning-to-rank frameworks that blend predicted engagement with business rules (boost new arrivals, penalize low-stock items, enforce category diversity) to balance user experience and operational goals.
Benefits and Business Impact of Recommendation Engines

Personalized recommendations consistently drive measurable revenue growth. Retailers report conversion rate improvements of 15 to 25% when relevant products appear at key decision points: product pages, cart summaries, and checkout. Average order value increases by 20 to 40% when complementary items and bundles surface alongside the primary purchase. One cosmetics brand measured an 11x improvement in purchase rate after deploying personalized recommendations across email and on-site placements.
Engagement metrics improve in parallel. Product views rise by approximately 40% when recommendations replace static merchandising. Click-through rates in personalized emails improve by 25 to 35%, and subject lines using personalization data are 26% more likely to be opened. Session duration extends when users discover relevant products without manual search. Cart abandonment decreases because well-timed accessory or alternative suggestions address hesitation. Showing a phone case at the moment a shopper adds a phone reduces friction and completes the mental shopping list. Retention compounds these gains: customers who experience relevant personalization return more frequently, and repeat purchase rates climb as the engine refines its understanding of individual preferences over time.
Implementation Framework for Ecommerce Recommendation Engines

Building a recommendation engine follows a structured sequence that balances quick wins with long-term scalability.
Start with one small dataset to prove the concept and establish measurement baselines. Most teams begin with homepage recommendations or product-page “You Might Also Like” widgets because those placements have high visibility and clear success metrics.
Data preparation and schema design: collect and structure three data categories: user behavior (clicks, views, purchases, add-to-cart, time on page), product metadata (titles, descriptions, categories, prices, images, stock status), and contextual signals (session timestamp, device type, referral source, geographic location). Unify event schemas across web, mobile, and email so all touchpoints feed the same feature store. Implement tracking for key conversion events and ensure privacy-compliant instrumentation.
Model selection and algorithm choice: choose collaborative filtering if interaction history is dense, content-based filtering if product metadata is rich or the catalog is new, and hybrid methods if both conditions apply. For catalogs under 100,000 SKUs, start with item-based collaborative filtering or k-nearest neighbors. For larger catalogs or real-time requirements, evaluate vector embeddings with ANN retrieval. Match algorithm complexity to team capabilities. Simpler models deploy faster and debug easier.
Integration with product catalog and user systems: connect the recommendation engine to product feeds for real-time inventory, pricing, and attribute updates. Sync user profiles or session state from authentication systems, CRM platforms, or customer data platforms. Expose recommendation results via REST APIs or GraphQL endpoints that frontend and email systems can call. Ensure API response times stay under 100 milliseconds to meet interactive UX requirements.
Training pipeline and feature computation: build batch jobs to compute historical features (total purchases per category, average session length, days since last visit) and streaming jobs to update in-session signals like recent clicks or cart additions. Store features in a feature store to synchronize training and serving. Train initial models on 60 to 90 days of interaction data, validate on a held-out test set, and retrain weekly or daily as new data accrues. Monitor training-serving skew by comparing feature distributions in both environments.
A/B testing and success measurement: roll out recommendations to 10 to 20% of traffic initially. Compare conversion rate, average order value, click-through rate, and revenue per visitor between the test group and a control group seeing static merchandising. Track metrics by placement (homepage, product page, cart, email) to identify which integration points deliver the highest lift. Use early stopping rules to retire underperforming variants quickly.
Deployment and operational monitoring: deploy the model behind feature flags for easy rollback. Set up monitoring for API latency (P50, P95, P99), error rates, cache hit ratios, and recommendation diversity (avoid showing the same five products to everyone). Implement graceful degradation. Fallback to popular or trending items if the recommendation service times out. Schedule regular load tests and conduct game days to surface queue backlogs, memory leaks, and noisy-neighbor problems before they hit production traffic.
Iteration is continuous. After the initial rollout, expand to additional placements (search results, abandoned-cart emails, social ads). Introduce new algorithms. Upgrade from item-based collaborative filtering to vector embeddings, or layer in a ranking model that optimizes for margin alongside relevance. Refine feature engineering based on observed performance gaps. Audit recommendation quality weekly by sampling outputs and checking for relevance, diversity, and alignment with current inventory and promotions.
Technical Integration Requirements

Recommendation engines require tight integration with existing ecommerce infrastructure to deliver sub-second personalization. API design is the primary integration surface: recommendation services expose endpoints for similar products, personalized suggestions, trending items, and cross-sell bundles. These APIs accept user identifiers (session ID, customer ID), context parameters (current product, cart contents, device type), and return ranked product lists with scores and metadata. REST and GraphQL are common transport layers, with WebSocket connections used for real-time updates during long sessions. Authentication typically uses bearer tokens, and rate limiting prevents abuse. API latency targets are strict. P95 response times must stay below 50 to 100 milliseconds because recommendations render during page load, and delays degrade user experience.
Data pipelines synchronize product catalogs and user behavior into the recommendation system. Product feeds update nightly or continuously via change-data-capture streams, pushing new SKUs, price changes, stock updates, and attribute modifications. User behavior flows through event streams (Kafka, Kinesis, Pub/Sub) that capture clicks, views, add-to-cart actions, purchases, and search queries in real time. Feature computation layers aggregate raw events into derived signals (category affinity scores, recent view counts, session duration) and write them to a feature store (Feast, Tecton) or low-latency database (Redis, DynamoDB). This architecture separates heavy computation from the serving path, keeping inference fast while training and feature updates run asynchronously.
Scalability depends on caching, replication, and hybrid query patterns. Pre-computing recommendations for high-traffic users or popular products reduces request-time load. One retailer pre-computes recommendations for tens of millions of users multiple times per day. Caching layers (Redis, CDN edge caches) store recent results and serve repeat requests without hitting the recommendation service. Vector databases (Milvus, Pinecone, Weaviate) store product and user embeddings, enabling approximate nearest neighbor searches that return top-100 candidates in under 30 milliseconds even across catalogs with 10 million SKUs. Hybrid queries combine vector similarity with structured filters (price range, category, in-stock) and full-text search in a single retrieval step, eliminating round-trips between multiple systems. Load balancing and auto-scaling handle traffic spikes during promotions or flash sales, and graceful degradation serves fallback recommendations (top sellers, trending items) when upstream services time out.
Leading Recommendation Engine Platforms

Most mid-market and enterprise ecommerce operators adopt managed recommendation platforms rather than building in-house. Managed platforms bundle data ingestion, model training, real-time serving, and A/B testing into a single service, accelerating time-to-value and reducing engineering overhead.
| Platform | Key Strength | Typical Use Case |
|---|---|---|
| Salesforce Commerce Cloud | Native integration with Salesforce CRM and Marketing Cloud. Unified customer profiles across commerce and service touchpoints. | Enterprise retailers with existing Salesforce ecosystems seeking omnichannel personalization across web, mobile, email, and in-store. |
| Dynamic Yield | Advanced experimentation framework. Supports multivariate testing and AI-driven optimization across dozens of recommendation strategies. | Brands running high-velocity A/B tests and personalization campaigns with complex segmentation and real-time decisioning. |
| Nosto | Fast deployment for SMB and mid-market. Visual merchandising tools for non-technical users. Strong email and on-site widget library. | Growing DTC brands needing quick wins without dedicated data science teams. Focus on homepage, product pages, and email. |
| Algolia Recommend | Unified search and recommendation API. Low latency (sub-50ms P95). Strong for browse-and-search hybrid experiences. | Retailers where product discovery blends search and recommendations. Catalogs requiring instant results and typo tolerance. |
| Google Recommendations AI | AutoML-powered models. Scales to billions of interactions. Integrates with Google Analytics and Google Ads for attribution. | Large-scale marketplaces and retailers with high SKU counts and deep event history. Teams comfortable with Google Cloud Platform. |
Platform choice depends on catalog size, traffic volume, in-house ML capabilities, and existing tech stack. Smaller catalogs under 10,000 SKUs and moderate traffic often start with Nosto or similar SMB-focused tools. Mid-market retailers with 50,000 to 500,000 SKUs and growing personalization ambitions evaluate Dynamic Yield or Algolia. Enterprises with millions of SKUs, complex omnichannel requirements, and dedicated data teams lean toward Google, AWS Personalize, or custom-built systems on vector databases. Integration depth matters: platforms that unify recommendations with search, email, and ads reduce the number of vendor relationships and data-syncing headaches.
Pricing Models for Recommendation Engines
Recommendation engine pricing varies by vendor, deployment model, and usage scale. Understanding cost structures helps teams budget accurately and avoid surprise overages as traffic grows.
Most SaaS platforms charge on usage-based tiers tied to API volume, monthly active users, or gross merchandise value. API-based pricing bills per thousand recommendation requests. Rates typically range from a few cents to several dollars per thousand calls depending on model complexity and response-time SLAs. MAU-based pricing charges per unique user receiving recommendations each month, with discounts at higher tiers. GMV-based pricing takes a percentage of attributed revenue, aligning vendor cost with business outcomes but requiring robust attribution tracking.
Usage-based pricing: charged per API call, recommendation impression, or personalized email sent. Scales with traffic but can spike during promotions. Typical for platforms like Algolia and Google Recommendations AI.
Subscription tiers: flat monthly or annual fee covering a set number of users, SKUs, or requests. Predictable budgeting but may require tier upgrades as business grows. Common for Nosto and mid-market SaaS tools.
GMV or revenue share: vendor takes 0.5 to 3% of revenue attributed to personalized recommendations. Aligns incentives but demands clear attribution methodology and integration with analytics platforms.
Enterprise contracts: custom pricing negotiated for high-volume deployments. Often includes implementation fees, dedicated support, SLA guarantees, and multi-year commitments. Typical for Salesforce Commerce Cloud and large-scale Google or AWS deals.
Implementation and onboarding fees add to total cost of ownership. Initial setup ranges from a few thousand dollars for plug-and-play SaaS to six figures for enterprise platforms requiring custom integration, data pipeline engineering, and multi-channel rollout. Ongoing operational costs include model retraining compute (especially for in-house systems), feature storage, API gateway fees, and internal engineering time for monitoring and optimization.
Case Studies and Real-World Results

A mid-sized fashion retailer integrated personalized recommendations across its product pages and abandoned-cart emails. Within 60 days, the retailer measured a 22% increase in conversion rate on product pages where “Complete the Look” suggestions appeared. Average order value rose 18% as shoppers added recommended accessories (belts, scarves, jewelry) alongside apparel. Abandoned-cart emails featuring personalized product grids saw click-through rates improve by 31% compared to generic reminders. Total attributed revenue from recommendations reached 19% of online sales within the first quarter.
An electronics marketplace deployed a hybrid recommendation engine combining collaborative filtering and vector embeddings to handle a catalog of 2.5 million SKUs. The system analyzed purchase co-occurrence, product specifications, and user browsing sequences to surface relevant accessories and alternatives. After launch, the marketplace observed a 27% lift in basket additions from homepage recommendations and a 15% reduction in cart abandonment when complementary items appeared at checkout. Search-to-purchase conversion improved by 12% after integrating recommendations into search result pages, showing related products alongside exact matches. The marketplace attributed nearly 2x revenue growth from search and recommendation touchpoints over the prior year.
A specialty grocery platform focused on repeat purchase behavior and seasonal trends. Recommendations prioritized frequently bought-together bundles (pasta and sauce, coffee and filters) and adjusted weights during holidays to promote gift sets and seasonal items. The platform set the system date to December during testing and confirmed higher scores for gift-worthy products and bundled offers. Post-launch metrics showed a 16% increase in repeat purchase rate and a 13% improvement in average basket size. Personalized weekly email campaigns highlighting past purchases and suggested restocks drove 29% higher click-through rates than category-based promotions.
Final Words
You learned how recommendation systems turn user behavior, product data, and context into tailored product picks that boost conversion and AOV.
We covered the main types: collaborative, content-based, and hybrid, plus core algorithms from k-nearest neighbors to deep learning and ranking methods.
We also walked through a clear implementation flow, integration needs, pricing models, vendor choices, and real-world lifts.
Start small: test product recommendations on your top 20 SKUs and watch conversion and AOV improve. An ecommerce recommendation engine can pay back fast.
FAQ
Q: What is an ecommerce recommendation engine?
A: An ecommerce recommendation engine is software that analyzes user behavior, product data, and context to suggest relevant products, boosting conversions, average order value, and customer retention.
Q: Why do recommendation engines matter for ecommerce?
A: Recommendation engines matter because they increase conversion rates, AOV, and repeat purchases by surfacing relevant items; retailers often see 20–40% AOV uplift and better customer retention.
Q: How do recommendation engines work at a high level?
A: Recommendation engines work by collecting behavior and product signals, processing them in real time, scoring item relevance with algorithms, and delivering ranked suggestions across site, cart, and email.
Q: What are the main types of recommendation systems?
A: The main types are collaborative filtering (patterns from similar users), content-based filtering (product attributes and metadata), and hybrid systems that blend both for better accuracy and coverage.
Q: Which algorithms power product recommendations?
A: Key algorithms include k‑nearest neighbors and matrix factorization for classic collaborative models, deep learning for complex patterns, reinforcement learning for sequences, and ranking layers optimized for engagement or revenue.
Q: What data inputs do recommendation engines need?
A: Recommendation engines need click and purchase events, product metadata, inventory and price data, session context (device, location), and explicit signals like ratings or wishlists to build accurate profiles.
Q: How do I implement a recommendation engine?
A: To implement a recommendation engine, prepare clean behavioral and product data, choose an algorithm, integrate with catalogs and tracking, train models, test outputs, then deploy with monitoring and iteration.
Q: What technical integrations are required?
A: Technical integrations require APIs for serving recommendations, synced product feeds, reliable event pipelines for tracking, low‑latency inference capabilities, and logging for offline retraining and debugging.
Q: How should I measure success and KPIs?
A: Measure success with conversion rate, average order value, revenue per session, repeat purchase rate, and model metrics like click‑through rate and prediction accuracy over defined test windows.
Q: Should I build or buy a recommendation platform?
A: Build versus buy depends on team, data scale, and speed needs: buy for faster rollout and robust tooling; build if you have strong data science, ops, and unique product signals to exploit.
Q: What are common pitfalls to watch for?
A: Common pitfalls include cold‑start and sparse data, poor product metadata, privacy compliance gaps, slow inference latency, and overfitting to short‑term clicks instead of revenue or retention.
Q: How are recommendation engines typically priced?
A: Pricing usually follows subscription, usage‑based API calls, or GMV/revenue share; expect costs to scale with traffic, API volume, personalization depth, and SLAs for latency and uptime.